Макаров Андрей.
Природа наградила человека двумя приёмниками звука (ушами). Именно наличие разнесённой пары приёмников предоставляет высшим отделам слуховой системы наиболее значимые параметры звука, необходимые для его локализации в пространстве: интенсивностна
Расстояние между ушами человека в среднем составляет 17,5 см. Если источник звука смещён в сторону, то расстояния, которые должна пройти звуковая волна до ближнего уха и до дальнего уха различаются. Эти различия сказываются на времени прихода звуковой волны – при скорости распространения звуковой волны в воздухе, равной 331 м/с, расстояние в 17,5 см звук преодолевает примерно за 0,5 мс. Звуковые волны разных частот имеют разную длину. На низких и средних частотах длины волн либо больше диаметра головы, либо сопоставимы с ним: они «огибают» голову и приходят в дальнее ухо за счёт эффекта дифракции. Звуковые волны более высоких частот встречают естественное препятствие, в результате чего в дальнее ухо попадают с заметно более низкой интенсивностью – голова выполняет роль экрана, формирует «акустическую тень» для большинства средне-высоких частот, из-за чего образуется разность интенсивности. 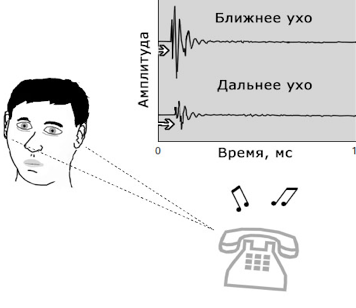 Сравнивая данные обоих слуховых каналов (отсюда и название «бинауральная») и выявляя разности в интенсивности и времени, слуховая система человека получает весьма точные сведения о нахождении источника звука в горизонтальной плоскости.
Сравнивая данные обоих слуховых каналов (отсюда и название «бинауральная») и выявляя разности в интенсивности и времени, слуховая система человека получает весьма точные сведения о нахождении источника звука в горизонтальной плоскости.
Влияния факторов интенсивностной и временной разности крайне велики. В частности, с помощью только одного лишь фактора интенсивностной разности можно «обмануть» человека, расположив виртуальный источник звука практически в любую точку между двумя акустическими системами в горизонтальной плоскости: достаточно увеличивать интенсивность одного из каналов, при этом звук будет плавно «смещаться» в его сторону (в современном оборудовании это реализовано регулятором «панорама»). Поэтому этот фактор является основополагающим для современной стереофонии. Фактор временной разности также играет значительную роль: с помощью внесения задержки в один из каналов можно достичь желаемого смещения виртуального источника звука вплоть до его крайнего положения. На различных частотах «запускаются» различные алгоритмы слухового анализатора человека (рис. 15): фактор интенсивностной разности превалирует от частоты 2 кГц, а при снижении частоты уменьшается и степень влияния данного фактора; фактор временной разности же эффективен до частоты ~400 Гц и его эффективность падает с ростом частоты. В частотном диапазоне от 400 Гц до 2 кГц работают оба эти фактора, но их влияние на оценку локализации нелинейно изменяется в зависимости от частоты. В случае, когда мы имеем дело с комплексным звуком, данную особенность следует учитывать, иначе, при моделировании виртуального источника звука, слуховая система человека начнёт получать заведомо противоречивые данные, которые не сможет достоверно «расшифровать». Следствием этого получится искажённое восприятие локализации, «размытый» образ. Особенно сильно данный эффект проявляется в случае с несколькими источниками звука в пространстве с многочисленными отражениями звуковых волн. В экспериментах по амплитудному панорамированию Вилле Пулкки и Матти Карьялайнена из Хельсинского Университета Технологии («Localization, coloration and enchancement of amplitude-panned virtual sources», 1999) была зарегистрирована ощутимая погрешность в локализации при использовании «стандартной» модели интенсивностного панорамирования на сигналах в области средних частот. Испытуемым предлагались для слепого прослушивания фрагменты записи узкополосного шума (1/3 октавы) с различными опорными частотами. Записи воспроизводились как с монофонической акустической системы, смещённой на 15°, так и со стереофонической пары (виртуальный источник также панорамировался на 15° – в ту же точку пространства). После прослушивания каждого из сигналов испытуемые указывали, где по их мнению располагался источник звука, и их оценки записывались.
При моделировании виртуального источника следует учитывать ещё один фактор, который присутствует при анализе звука реальной слуховой системой человека. Как уже говорилось ранее, голова имеет свойство экранировать звук. При этом, экранирование также носит крайне неравномерный характер, так как голова имеет весьма сложную форму, а её поверхность неоднородна и обладает различными отражающими свойствами. Дополнительные уникальные частотные искажения в зависимости от угла падения звуковой волны вносит и форма ушной раковины. Всё это приводит к тому, что при различных углах смещения источника звука «затенение» дальнего уха и даже характер звука в ближнем ухе будут отличаться (изменяется спектральная составляющая звука). Эффекты затенения измеряются экспериментально и носят название Head Related Transfer Functions (HRTF, Передаточные Функции Головы и Ушных раковин). Использование одновременно факторов интенсивностной и временной разности, а также HRTF позволяет уже максимально достоверно моделировать положение виртуального источника звука в горизонтальной плоскости. В частности, упомянутые выше учёные Хельсинского Университета Технологии разработали и испытали бинауральный процессор, учитывающий нелинейные согласования факторов временной и интенсивностной оценки реальной слуховой системы человека, а также спектральные искажения, вносимые HRTF (реализовано посредством фазолинейного эквалайзера, основываясь на нормированных измеренных данных). При панорамировании звука с использованием данного процессора погрешность оценок локализации звука у испытуемых уменьшилась в среднем на 4-5° относительно погрешности при простом амплитудном панорамировании, а в проблемных частотных областях (1-3 кГц) – на 10°-12°. Подобные процессоры на сегодняшний день присутствуют в виде разнообразных программных продуктов: как плагины (к примеру, Wave Arts Panorama) или как встроенный набор инструментов (аудиоредактор Logic Pro). Возможно, через определённое время подобные решения станут стандартными для индустрии звукозаписи.Описанные выше основные принципы бинаурального восприятия звука человеком, несмотря на неоспоримую значимость, являются далеко не исчерпывающими для локализации источника звука в объёмном пространстве. До сих пор, описывая временную и интенсивностную разность, мы рассматривали только горизонтальный план, причём, пространство между акустическими системами перед слушателем. В реальном же мире источник звука может располагаться не только правее/левее, но и ближе/дальше, ниже/выше, да и вообще позади слушателя. Главным недостатком бинауральной теории является тот факт, что она реально «работает» только при условии разности звуковых данных в левом и правом ухе. В случае же равных «сигналов» теория даёт сбой.
Первая проблема в бинауральной теории – оценка расстояния до источника звука. Дело в том, что временная и интенсивностная разность между слуховыми каналами на неё практически не влияет. Более того, когда источник звука располагается строго на центральной оси слушателя, звуковые волны, приходящие от источника в левое и правое ухо, абсолютно равны. При этом реальная слуховая система человека продолжает оценивать расстояние до источника.
Эмпирическим путём ещё в начале прошлого столетия были обнаружены несколько факторов, которые позволяют слуховой системе определить расстояние до источника звука.
Первым фактором стоит отметить общий уровень интенсивности сигнала. На низких частотах, где длина волны большая (5-15 м), источник звука можно считать точечным, а звуковые волны вокруг него – сферическими. В сферической волне площадь поверхности увеличивается пропорционально квадрату расстояния, и следовательно звуковое давление падает обратно пропорционально расстоянию. То есть при увеличении расстояния от источника звука до слушателя в 2 раза звуковое давление также снижается в 2 раза (6 дБ). Данные предположения оправдывались в ходе многократных экспериментов при объективных измерениях. Однако при попытках имитировать увеличение расстояния до источника звука, субъективное ощущение его удвоения возникало только при уменьшении уровня звукового давления на 20 дБ, а не на 6 дБ, как при объективных измерениях. Это даёт основания полагать, что сам по себе фактор интенсивности не является решающим.
Вторым фактором при оценке расстояния является частотная характеристика звукового сигнала. Высокочастотные составляющие звукового сигнала с расстоянием затухают быстрее низкочастотных. В результате, на расстояниях более 15 м спектр звука имеет ярко выраженный спад в области высоких частот. На расстояниях же меньше 3 м в силу вступают дифракционные эффекты, оказываемые ушными раковинами и головой, влияя на интенсивность и задержки средних частот.
Третий фактор – интенсивность отражённых звуковых волн. Ещё с начала прошлого столетия подмечено, что при её увеличении расстояние до источника звука субъективно увеличивается. Данным фактором успешно пользуется индустрия звукозаписи на протяжении уже почти века. На сегодняшний день существует огромное разнообразие эффект-процессоров, эмулирующих многократные отражения звука (создающих эффект реверберации) и позволяющих с помощью них не только «украшать» звук, но и управлять его «близостью» к слушателю. С точки зрения бинауральной теории сам механизм выделения слуховой системой «чистого» звука на фоне отражённого остаётся непонятым. Не поддаются объяснению также и факторы влияния на оценку расстояния общей интенсивности сигнала и его спектральных изменений.
Одним из самых желанных достижений современной аудио-индустрии является возможность реализовывать расположение источника звука в вертикальной плоскости относительно слушателя. На сегодняшний день существует множество экспериментальных многоканальных систем объёмного звучания: Ambisonics, Auro-3D, DolbyAtmos, Wave Field Synthesis (WFS). Перед инженерами стоят два метода реализации вертикальной локализации: добавление акустических систем в места предполагаемых источников звука (моделирование реального источника) и применение принципов бинауральной стереофонии для реализации виртуальных источников между акустическими системами вертикальной плоскости. Наиболее интересным смотрится второй вариант, так как он позволяет моделировать виртуальный источник звука в любой позиции при помощи всего лишь пары (в идеале) систем (как стереофония в горизонтальной плоскости). Однако практическая реализация второго варианта испытывает явные затруднения. Во-первых, исследования Университета Хаддерсфилда (Х. Ли, К. Гриббен, Р. Уоллис) показали, что влияние интенсивностной разности при «вертикальном стерео» приводит не к плавному смещению виртуального источника звука, а к полной маскировке одного из реально используемых громкоговорителей системы (мнимый источник перемещается только в крайние положения). В связи с этим, эксперименты свелись к использованию временных разностей между каналами. Как показали результаты, моделирование управляемого виртуального источника, путём внесения временных задержек в вертикальный канал, также практически невозможно даже при использовании специальных фильтров (известна тенденция слуховой системы человека высокочастотные звуки «располагать» несколько выше в вертикальной плоскости). Хоа-Ван Нгуен и Эрве Лиссек в своей работе “Vertical localization performance in a practical 3-D WFS formulation” предприняли иной подход: использовалась большая многоканальная система WFS из 24 независимых акустических систем с несколькими рядами вертикальных уровней и сложными алгоритмами расчёта звукового поля внутри системы. В данном случае исследователи рапортуют о достижении 5 градаций вертикального уровня между 14° и 58° (точность достигает 6°-9°). Несмотря на то, что для практических целей данных результатов вполне достаточно, реализация подобных систем крайне затруднительна, а о реальной управляемости виртуальным источником в данном случае говорить не приходится (настоящие источники звука – акустические системы, – просто «совпадают» с виртуальными). Одним из главных выводов многих проводимых подобных исследований является то, что принципы бинаурального восприятия горизонтального плана в вертикальном плане попросту не работают.
Расположение источника звука в тыловой части реализуется сегодня при помощи дополнительных акустических систем. В данном случае принципы бинауральной теории хорошо применимы, и виртуальный источник полностью управляем посредством всего двух тыловых акустических систем. А в совокупности с фронтальными системами источник звука может быть расположен в любой точке горизонтальной плоскости, что прекрасно реализуется в современных системах Dolby Digital и DTS. Однако при попытке реализовать тыловое расположение без использования дополнительных громкоговорителей, принципы бинауральной теории оказываются практически неприменимы.
Термин «монауральная» может показаться несколько запутывающим и неуместным, однако в данной работе он используется по ряду причин. Во-первых, данный термин подчёркивает ключевое отличие монауральной теории от бинауральной – акцентированное изучение данных только одного слухового канала (уха) с целью выявления его способности локализации источника звука и определения факторов, влияющих на точное позиционирование (отсюда приставка «моно-»). Во-вторых, многие зарубежные исследователи, ведущие изыскания по данной теме, используют именно этот термин (англ. – monaural).
Так как факторы временной разности и разности интенсивностей, на которые опирается бинауральная теория, не позволяют полностью объяснить объёмного пространственного восприятия звука, была выдвинута гипотеза о том, что слуховая система человека может эти факторы «игнорировать», рассматривая при этом факторы монауральные. Основным предположением теории является наличие всех необходимых факторов для определения источника звукового сигнала в пространстве в каждом отдельном слуховом канале. Это кажется маловероятным, и долгое время психоакустика отказывалась принимать данное положение. Но недавние медицинские исследования показали способность некоторых людей, полностью глухих на одно ухо, достоверно определять пространственное положение источников звука как по горизонтали, так и по вертикали (документировано в работах Слаттери и Миддлбрукса, а также Ван Ванрооя и Ван Опстала).
Главным предметом исследования и анализа монауральной теории являются HRTF. В отличие от упрощённых моделей (достигаемых при помощи эквализации), используемых в некоторых случаях в бинауральных процессорах, исследователи в данном направлении записывают и используют в своих тестовых моделях импульсы HRTF реальных людей с помощью миниатюрных микрофонов.
Записываются различные положения реального источника звука относительно слушателя, как правило, в безэховой камере. Экспериментально установлено, что если обработать любой записанный звуковой сигнал с помощью импульсов HRTF (операция математической свёртки функций – подобный подход применяется в современных продвинутых эффект-процессорах), то при его прослушивании воссоздаётся виртуальное расположение источника, полностью совпадающее с тем, которое использовалось при записи импульсов. Такие впечатляющие результаты возможны только при соблюдении строгих условий. Во-первых, HRTF должна быть «родной» для слушателя – при использовании HRTF другого человека точность локализации образа нарушается (но не исчезает полностью). Во-вторых, необходимо устранить взаимопроникновение звуковых каналов, что означает возможность прослушивания только в головных телефонах. Впрочем, в своей работе “Head-Related Transfer Functions and their role in the localization of sound sources in human listeners “ Пётр Майдак заявляет о воссоздании положения виртуального образа сзади слушателя посредством пары акустических систем, расположенных перед ним. Результаты П. Майдака при прослушивании на внешних акустических системах были достигнуты в лабораторных условиях с применением средств подавления межканальной интерференции. К сожалению, повторить подобный опыт в обычных условиях крайне затруднительно.
Даже при использовании «неродных» импульсов HRTF, но при прослушивании в головных телефонах, эффект локализации источника звука достаточно явно прослеживается. В рамках продвижения своей книги “Auditory neuroscience: making sense of sound” Ян Шнупп, Израель Нелкен и Эндрю Кинг организовали Интернет-ресурс, на котором в рекламных целях размещены различные медиа материалы. Среди них присутствует минипрограмма, демонстрирующая возможности эмуляции виртуального положения в пространстве с помощью свёртки (используется HRTF одного из авторов книги) – http://auditoryneuroscience.com/topics/VAS.
Несмотря на достигнутые результаты, теория не даёт точных ответов на вопросы о функционировании механизмов, отвечающих за локализацию источника звука в слуховой системе человека. Современные исследователи пытаются найти закономерности в изменениях спектральных составляющих HRTF различных точек пространства. Иногда проводятся эксперименты, имитирующие весьма неестественные условия, с целью «нащупать» неизвестные факторы. К примеру, эксперименты с «прореживанием» спектра тестового сигнала Макферсона и Миддлбрукса. В ходе данных экспериментов использовался широкополосный шум, который подвергался частотной обработке: в спектре узкими полосами подавлялись («вырезались») несколько частотных областей. Подобным образом было создано несколько тестовых сигналов, в которых вырезались различные частотные компоненты. В дальнейшем полученные тестовые сигналы воспроизводились испытуемым через громкоговоритель, расположенный в различных точках пространства (в основном, исследовалась зависимость вертикальной локализации). На некоторых тестовых сигналах обнаруживались серьёзные затруднения и погрешности в локализации источника звука, что позволило сделать предположение о важности вырезанных частот для её оценки. Результаты данного эксперимента использовались в построении собственной теоретической модели пространственного звукового восприятия Петром Майдаком и Робертом Баумгартнером (“Modeling sound-source localization in sagittal planes for human listeners”, 2014).
При бинауральном анализе слуховая система человека использует для оценки сигналы, приходящие с левого и правого уха. Одномоментное наличие двух сигналов позволяет слуховому анализатору выявлять разницу между ними и, уже основываясь на ней, вычленять факторы, необходимые для оценки расположения источника звука в пространстве. В монауральном анализе одномоментно присутствует только один сигнал. Отсюда вытекает одна из проблем монауральной теории – не ясно, каким образом слуховая система человека определяет интересующие её факторы из данных одного слухового канала. Исследователи сходятся во мнении, что слуховой анализатор по-прежнему производит процесс сравнения сигналов, однако элементы данного сравнения учёные видят различными. Условно можно выделить два основных теоретических подхода: абсолютный и относительный.
Наиболее популярным является подход абсолютный, который предполагает наличие у человека многочисленных «акустических шаблонов», формирующихся у человека в процессе развития и взросления и постоянно корректирующихся. Считается, что любой звук проходит проверку согласно этим шаблонам, и на её основе вычисляется положение источника звука (а также, возможно, и высота и некоторые другие характеристики). Пример использования данного подхода можно увидеть в работе Р. Баумгартнера и П. Майдака “Modeling sound-source localization in sagittal planes for human listeners” (2014). Абсолютный подход предлагает достаточно простое и стройное решение, однако оставляет ряд вопросов и критических замечаний. Во-первых, предполагается наличие невероятно большого количества шаблонов: слуховая система человека должна знать, как «ведёт себя» сигнал в каждой конкретной точке пространства; распознавать многочисленные акустические окружения; и при этом понимать, как изменяются различные тембры в разнообразных условиях. Способность человеческого мозга держать в себе (и постоянно корректировать) такой огромный объём информации кажется сомнительной. Более того, нередки случаи попадания человека в абсолютно незнакомое акустическое окружение с незнакомыми звуками (к примеру, голос незнакомого человека в не посещённом до этого доме) – отсутствие шаблонов должно было бы сделать локализацию источника звука невозможной (до «полного знакомства»), однако в реальной жизни это не так. Во-вторых, процесс формирования шаблонов предполагает задействование визуальных и тактильных ощущений и даже ставит слуховую систему в зависимое от них положение. Иными словами, при отсутствии визуального контроля в незнакомом окружении у человека должна пропадать и способность к акустической локализации, что снова противоречит реальным опытам – после непродолжительной адаптации человек весьма достоверно определяет положение источника звука в пространстве без визуального и тактильного контроля. В-третьих, процесс формирования шаблонов напрямую зависит от физиологии конкретного человека, что означает, что они сугубо индивидуальны. Данное положение ставит под сомнение существование универсальных действенных факторов, на которые реагирует слуховая система человека в целом, а это, в свою очередь, противоречит практическим целям монауральной теории, так как в таком случае поиск общих закономерностей бесполезен.
В качестве альтернативы рядом других учёных предлагается относительный подход. Суть его заключается в том, что сравнение сигнала происходит с самим собой, но через определённый промежуток времени. Предполагается, что система анализирует и интегрирует небольшие временные отрезки – «кадры», – производит автокорреляцию сигнала, и на основе её результатов выявляет необходимые закономерности (факторы локализации).
Исследователи предлагают разные размеры «кадра» – от 5 мс до 40 мс. К примеру, упомянутые ранее Вилле Пулкки и Матти Карьялайнен при построении своей теоретической модели и реализации бинаурального процессора (“Localization, coloration and enchancement of amplitude-panned virtual sources”, 1999) для расчёта весовой функции влияния временного и интенсивностного факторов использовали временной отрезок, длиною 10 мс. Гипотетически, анализ двух рядом идущих «кадров» позволяет определить очень точную фазовую структуру сигнала и выявить фронт звуковой волны. Имея такие данные, слуховая система уже может идентифицировать первичную и отражённую звуковые волны. Косвенным подтверждением использования механизмов описываемого относительного подхода в реальной слуховой системе человека можно считать открытыйв 1949 г. эффект предшествования, позже известный как эффект Хааса. Опытным путём было установлено, что слух человека выделяет только первый из серии одинаковых звуков, идущих во временном промежутке, меньшем, чем 30 мс (зависит от характера звука). Остальные же звуки слуховая система «усредняет» или игнорирует. Данная способность позволяет локализовать источник в закрытых пространствах с большим количеством отражений, «абстрагируясь» от них. Если учесть описываемые ранее эффекты дифракции звуковых волн, вызванные строением головы и ушных раковин, то можно предположить наличие небольших фазовых искажений различных частотных компонентов сигнала, изменяющихся в зависимости от угла прихода звуковой волны. Такие искажения неизбежно скажутся на характере её фронта – некоторые частотные компоненты будут появляться быстрее на несколько миллисекунд, чем другие, а на более длительном временном промежутке будет заметна флуктуация их амплитуд (рис. 20). Возможно, слуховой анализатор выделяет фазовый спектр фронта волны и сравнивает его с имеющимся унифицированным шаблоном, а полученная в результате этого разность уже содержит важную информацию о локализации источника звука. Впрочем, данный вопрос требует детального изучения. Недостатком относительного подхода можно считать невозможность вычленения значимых факторов локализации, основанных на амплитудном спектре сигнала, так как он практически идентичен для двух рядом идущих «кадров».
Главной проблемой в развитии монауральной теории является сложность анализа происходящих процессов. К примеру, для изучения влияния фазовых искажений HRTF стандартная математическая модель анализа – преобразование Фурье, – неприменима, так как время исследуемого сигнала едва превышает 5 мс, что слишком мало для анализа с большим частотным разрешением. Вариантом решения проблемы могут послужить вейвлет-преобразования, приспособленные для работы с короткими сигналами.